目次
概要
EC2インスタンスの上でELBに紐付くECSタスクを動かす場合、EC2インスタンスを落とす前にECSタスクをELBから抜く必要があります。従来はAutoScalingGroupのLifeCycleHookからLambdaを叩き、そこでECSに停止処理を行っていました。この面倒な処理を簡単に行うことができる「マネージドインスタンスドレイン」機能がリリースされました。ここでは、マネージドインスタンスドレインの導入事例を説明します。
そもそも何が問題なのか
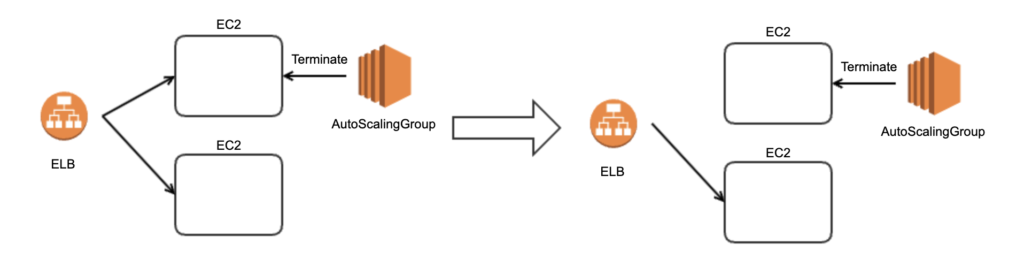
EC2の上で動くアプリケーションをAutoScalingGroupで管理するとき、ELBはAutoScalingGroupと紐付きます。AutoScalingGroupがインスタンスを終了するとき、ロードバランサーから抜けるのを待ってからEC2インスタンスを終了させます。
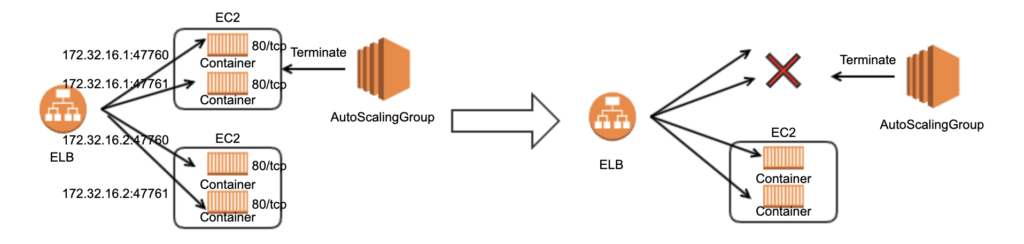
1台のEC2の上で複数のコンテナを動かす場合、ECSを使って管理する方法があります。複数コンテナが同じポートを利用できないため、dockerのポートマッピング機能で異なるポートを公開します。無数のコンテナのポートを指定するのは現実的では無いので、ECSの動的ポートマッピング機能で公開するポートを決めます。ロードバランサーは公開ポートと通信するため、それを管理するECSと紐付けます。
このケースではAutoScalingGroupは公開しているポートを把握していないため、ロードバランサーと紐付けることはできません。AutoScalingGroupがインスタンスを終了するとき、ロードバランサーと紐付いていないため、即時にEC2インスタンスを終了させます。ロードバランサーは、ヘルスチェックが失敗するまで終了したインスタンスに対してリクエストを送り続けます。レスポンスは502 Bad Gatewayとなり、CloudWatchでHTTPCode_ELB_502_Countの値として確認できます。
つまり、ロードバランサーから抜ける前にECSタスクが終了してしまっていることが問題です。
従来の解決方法
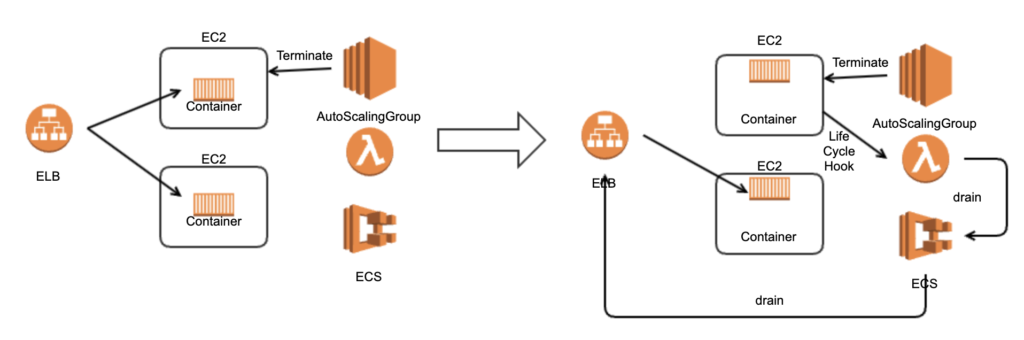
この問題を解決するためには、ロードバランサーからECSタスクを抜いてから止める必要があります。AutoScalingGroupにはLifeCycleHookという機能があり、これを使ってEC2インスタンスの終了処理に介入することができます。CloudFormationのtemplateで書くと、以下のようになります。
Parameters:
EcsInstanceAsg:
Type: String
Resources:
ASGTerminateHook:
Type: "AWS::AutoScaling::LifecycleHook"
Properties:
AutoScalingGroupName: !Ref EcsInstanceAsg
DefaultResult: "ABANDON"
HeartbeatTimeout: "900"
LifecycleTransition: "autoscaling:EC2_INSTANCE_TERMINATING"
NotificationTargetARN: !Ref ASGSNSTopic
RoleARN:
Fn::GetAtt:
- "SNSLambdaRole"
- "Arn"
DependsOn: "ASGSNSTopic"
上記LifeCycleHookが叩かれると、SNSに通知されます。SNSからLambdaが起動されます。
ASGSNSTopic:
Type: "AWS::SNS::Topic"
Properties:
Subscription:
-
Endpoint:
Fn::GetAtt:
- "LambdaFunctionForASG"
- "Arn"
Protocol: "lambda"
DependsOn: "LambdaFunctionForASG"
Lambdaで対象ECSタスクのステータスをDRAININGに変更し、ロードバランサーから対象ECSタスクへのリクエストを停止します。
ECS.update_container_instances_state(cluster=CLUSTER,containerInstances=[instance_arn], status='DRAINING')ECSタスクの状態を確認し、実行中なら30秒待って再度自分自身を起動するようSNSに通知します。
停止済みなら対象のLifeCycleHookを終了し、EC2インスタンスが終了可能な状態となります。
def lambda_handler(event, context):
msg = json.loads(event['Records'][0]['Sns']['Message'])
if 'LifecycleTransition' not in msg.keys() or \
msg['LifecycleTransition'].find('autoscaling:EC2_INSTANCE_TERMINATING') == -1:
print('Exiting since the lifecycle transition is not EC2_INSTANCE_TERMINATING.')
return
if instance_has_running_tasks(msg['EC2InstanceId']):
print('Tasks are still running on instance %s; posting msg to SNS topic %s' %
(msg['EC2InstanceId'], event['Records'][0]['Sns']['TopicArn']))
time.sleep(30)
sns_resp = SNS.publish(TopicArn=event['Records'][0]['Sns']['TopicArn'],
Message=json.dumps(msg),
Subject='Publishing SNS msg to invoke Lambda again.')
print('Posted msg %s to SNS topic.' % (sns_resp['MessageId']))
else:
print('No tasks are running on instance %s; setting lifecycle to complete' %
(msg['EC2InstanceId']))
ASG.complete_lifecycle_action(LifecycleHookName=msg['LifecycleHookName'],
AutoScalingGroupName=msg['AutoScalingGroupName'],
LifecycleActionResult='CONTINUE',
InstanceId=msg['EC2InstanceId'])
この方法では、LifeCycleHookやlambdaなどを自分で用意する必要があります。よく使われるパターンですので、AWS側がECSの機能として提供するようになりました。それが、マネージドインスタンスドレインです。
新たな解決方法
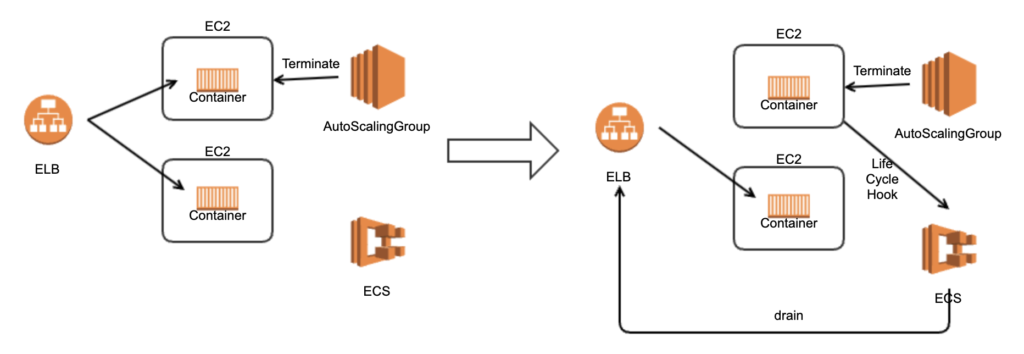
仕組みとしては、上記の「従来の解決方法」とほとんど同じものです。Lambdaが消えているため、構築や保守の負担が減ります。以下では、AWS Consoleを使った設定方法を説明します。
AWS ConsoleでECSクラスターの画面を開きます。インフラストラクチャータブで、作成をクリックします。

スケーリングポリシーで、「マネージドインスタンスのドレインを有効にします。」にチェックを入れ、作成ボタンをクリックします。
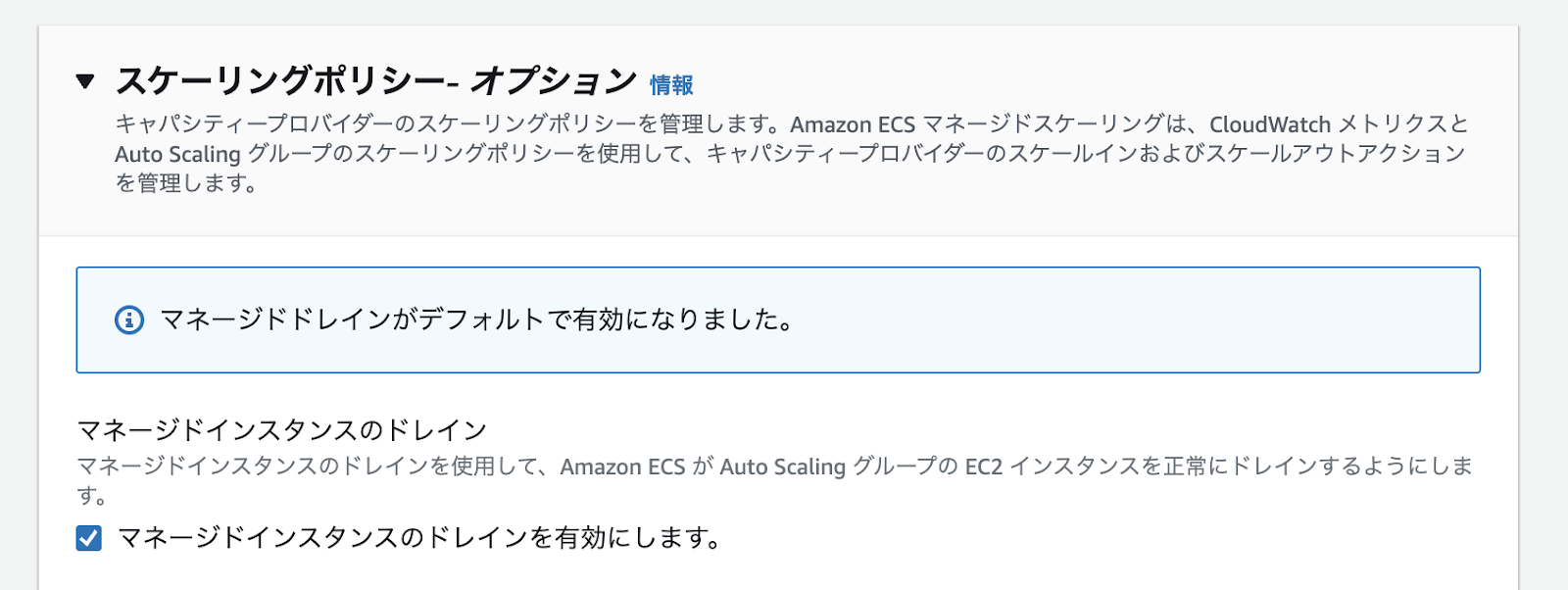
これだけです。AutoScalingGroupのライフサイクルフックには、通知ターゲットが空で追加されていることが確認できます。

terraformでは、近日リリース予定のTerraform AWS Provider v5.34.0で提供される予定です。これがリリースされれば、以下のように1行書くだけで実現できるようになります。
managed_draining = "ENABLED"
まとめ
面倒なLifeCycleHook周りの設定やメンテナンスから解放されるのは、地味に嬉しいことです。設置済みの仕組みを入れ替えるほどではありませんが、新規設置やメンテナンスのタイミングで置き換えてみてはいかがでしょうか。皆様の業務に少しでもお役に立てれば幸いです。
